Ever been knees deep (I said knees) in code and wondering why a BC is being read and a GC etc etc

Here is a handy refernce from oracle for what they are and when they are populated
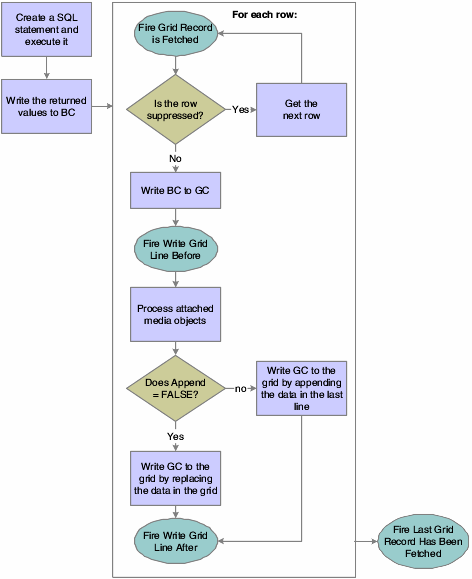
Note that you might need to also view some of these flows to know exactly when a GB is written to a GC… https://docs.oracle.com/cd/E17984_01/doc.898/e14706/grid_controls.htm#g8d6ab57f7cedeaac_ef90c_10a77c8e3f7__7257
| Available Object Code | Description |
|---|---|
| BC | A column in the business view (BV). BCs for both the form view and the grid view appear in this list. The system fills these columns with values from the database when it performs a fetch. The system writes these values to the database during an add or update. |
| GC | A column in the grid. The row that the value references depends on which event is accessing the GC. During the fetch cycle, it is usually the selected row. In some circumstances, CG objects also denote a particular physical column in the grid instead of a value. An example is the Set Grid Font system function. |
| GB | The grid buffer. This buffer is one row of data that is independent of the lines that the system reads from the database and writes to the grid. The GB enables you to manipulate column data for a line that you want to insert or update without affecting the present state of the grid. You access the GB through an available GB object, which appears after the GC objects in the list of available objects in Event Rules Design. Each grid contains only one instance of each GB column. |
| FC | A control on the form. If the control is a database item, this field corresponds to a BC object. Furthermore, if the control is not a filter, the FC object represents the same value as the BC object, and changing one of these results in changing both. |
| FI | A value passed through a form interconnection. You access this object either to read values that are passed into the form or to set values to be passed back. These objects correspond to the elements of the form data structure. |
| PO | A value passed from a PO. These values are passed into the application when a user launches it. Any form in that application can access them. POs can either be entered by the user, or they can be set up in a particular version of an application. |
| QC | A cell from the QBE line in the grid. These objects represent the values in any QBE cell on the grid. They include wild cards, but do not include any comparison operators. Likewise, assignments to these objects can include wild cards, but not comparison operators. To set comparisons, you must use a system function. |
| HC | A hypercontrol item. A hypercontrol item is a menu item or a tool bar item. |
| VA | ER variables. These objects represent any variables that you set up in ER. |
| SV | System variables. These objects represent some environment variables that are accessible to ER. |
| SL | System literals. These objects represent some constant system values that are accessible to ER. |
| TP | Tab page object. |
| TK | A column in the table that contains the table ER. |
| CO | A constant, such as the return code for an error. |
| TV | Text variables. |
| RC | Report constants for a batch application. |
| RV | Report variables (batch application). |
| IC | An input column (table conversion). |
| OC | An output column (table conversion). |






